Kimi K2: Moonshot AI's Trillion-Parameter Open Agentic Intelligence Model
The field of Artificial Intelligence is experiencing a paradigm shift toward Agentic Intelligence – the capability for models to autonomously perceive, plan, reason, and act within complex environments. At the forefront of this revolution stands Kimi K2, Moonshot AI's latest masterpiece that redefines what's possible with open-source large language models.
Source: All technical information and performance data in this post are based on the Kimi K2 Technical Report and official Moonshot AI announcements.
What is Kimi K2?
Kimi K2 is a groundbreaking 1.04 trillion-parameter Mixture-of-Experts (MoE) large language model with 32 billion activated parameters, purposefully designed for agentic intelligence. Unlike traditional language models that focus on text generation, Kimi K2 is engineered as an intelligent agent capable of autonomous planning, tool usage, and complex task execution.
The model represents a paradigm shift from static imitation learning toward models that actively learn through interactions, acquire new skills beyond their training distribution, and adapt behavior through experiences. This positioning makes Kimi K2 not just a text generator, but a sophisticated agent capable of real-world problem-solving.

Revolutionary Technical Innovations
Kimi K2's breakthrough performance is built on three foundational pillars of innovation:
1. MuonClip Optimizer: Solving the Stability-Efficiency Dilemma
The most significant technical achievement is MuonClip, a novel optimizer that successfully harnesses the token-efficient Muon algorithm while addressing its notorious instability issues.
The Challenge: Muon is a quasi-second-order optimizer that achieves superior token efficiency through momentum-aligned sign updates (msign), but it suffers from training instability due to exploding attention logits, particularly in the query (Wq) and key (Wk) matrices.
The Solution: MuonClip introduces QK-Clip, a per-head negative feedback control mechanism that monitors attention logits during forward passes. When a head's logits exceed a preset threshold (τ), the system applies corrective scaling factors only to the non-shared query and key projection matrices of that specific head.
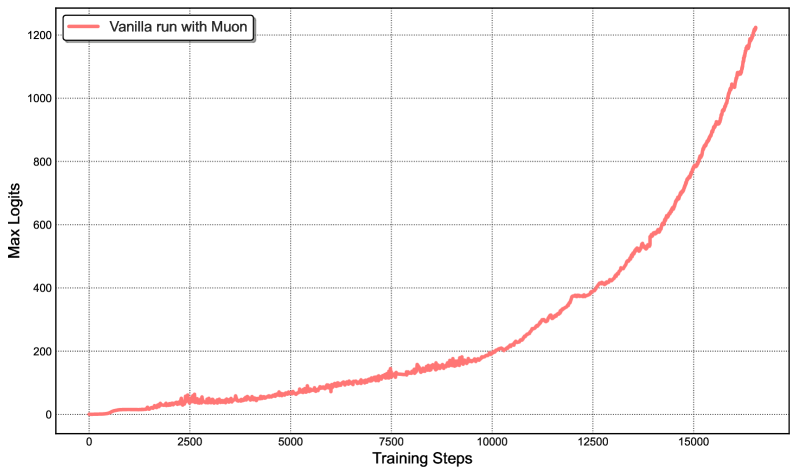

Unprecedented Achievement: Kimi K2 was successfully pre-trained on 15.5 trillion tokens with zero loss spikes – a historic milestone for trillion-parameter model training.

2. Industrial-Scale Agentic Data Synthesis
Kimi K2 employs a sophisticated "agentic skill factory" that systematically generates tool-use demonstrations at scale:
- Tool Repository: Over 23,000 tools combining real-world MCP (Model Context Protocol) tools from GitHub and synthetic tools across diverse domains
- Rubric-Based Task Generation: Each task comes with machine-readable success criteria, eliminating human judgment ambiguity
- Multi-Turn Trajectory Generation: Realistic interactions including retries, error handling, and complex decision patterns
- Quality Evaluation: LLM-based verification stack ensures only high-quality, correct samples are retained

3. Verifiable Rewards and Self-Critique Framework
Kimi K2 implements a dual reinforcement learning approach:
RLVR (Reinforcement Learning with Verifiable Rewards): For objective tasks like coding, the model receives clear, binary reward signals based on verifiable outcomes (e.g., test passage).
Self-Critique Rubric Reward: For subjective qualities, a critic model evaluates the actor's outputs, but only after proving its judgment capabilities on objective tasks from RLVR.
This creates a recursive, self-reinforcing loop that grounds subjective alignment in objective, verifiable foundations.
Architecture Excellence: Designed for Agentic Efficiency
Core Specifications
| Parameter | Value |
|---|---|
| Architecture Type | Mixture-of-Experts (MoE) |
| Total Parameters | 1.04 Trillion |
| Activated Parameters | 32 Billion |
| Number of Layers | 61 |
| Dense Layers | 1 |
| Total Experts | 384 |
| Experts per Token | 8 |
| Sparsity Ratio | 48 |
| Attention Heads | 64 |
| Context Length | 128K |
| Attention Mechanism | Multi-head Latent Attention (MLA) |
Strategic Design Choices
Ultra-High Sparsity: With a sparsity ratio of 48 (384 total experts / 8 active experts), Kimi K2 demonstrates the effectiveness of the sparsity scaling law – achieving massive model capacity while maintaining computational efficiency.

Optimized Attention Architecture: The choice of 64 attention heads (half of DeepSeek-V3's 128) represents a deliberate trade-off. While more heads might provide marginal performance gains, the inference cost would double – a critical consideration for agentic applications requiring long-context processing.
Multi-head Latent Attention (MLA): Borrowed and refined from DeepSeek-V3, MLA reduces computational overhead through compressed latent vectors while maintaining the shared and non-shared component structure essential for MuonClip's stability mechanism.
Performance Leadership Across Domains
Kimi K2 achieves state-of-the-art performance across multiple critical benchmarks:
Coding and Software Engineering Excellence
| Benchmark | Kimi K2-Instruct | DeepSeek-V3 | GPT-4.1 | Claude 4 Opus |
|---|---|---|---|---|
| SWE-Bench Verified (Single) | 65.8% | 38.8% | 54.6% | 72.7% |
| SWE-Bench Verified (Multi) | 71.6% | - | - | 80.2% |
| LiveCodeBench v6 | 53.7% | 46.9% | 44.7% | - |
| OJBench | 27.1% | 24.0% | 19.5% | 19.6% |
Agentic Tool Use Mastery
| Benchmark | Kimi K2-Instruct | DeepSeek-V3 | GPT-4.1 | Claude 4 Opus |
|---|---|---|---|---|
| Tau2 Retail | 70.6% | 69.1% | 74.8% | 81.8% |
| Tau2 Airline | 56.5% | 39.0% | 54.5% | 60.0% |
| Tau2 Telecom | 65.8% | 32.5% | 38.6% | 57.0% |
| ACEBench (En) | 76.5% | 72.7% | 80.1% | 75.6% |
Mathematical and STEM Reasoning
| Benchmark | Kimi K2-Instruct | DeepSeek-V3 | GPT-4.1 | Claude 4 Opus |
|---|---|---|---|---|
| AIME 2024 | 69.6% | 59.4% | 46.5% | 48.2% |
| MATH-500 | 97.4% | 94.0% | 92.4% | 94.4% |
| GPQA-Diamond | 75.1% | 68.4% | 66.3% | 74.9% |
Real-World Recognition
On the LMSYS Arena leaderboard (July 17, 2025), Kimi K2-Instruct ranks as the #1 open-source model and #5 overall based on over 3,000 user votes, demonstrating its excellence in real-world applications.
Advanced Training Infrastructure
Kimi K2's success is also built on sophisticated infrastructure innovations:
Efficient Resource Management
- Colocated Architecture: Training and inference engines share the same workers, switching resources dynamically
- Distributed Checkpoint Engine: Manages parameter updates across thousands of GPUs with minimal overhead
- Activation Reduction: Selective recomputation, FP8 storage, and CPU offloading optimize memory usage

Agentic Rollout Capabilities
- Heavy Environment Services: Scalable deployment for complex tool interactions
- Concurrent Rollout Management: Thousands of parallel trajectories to maximize GPU utilization
- Partial Rollout Technique: Long-tail tasks can be paused and resumed across iterations
Data Innovation: Rephrasing for Token Efficiency
Beyond architecture, Kimi K2 introduces novel data augmentation techniques:
Knowledge Data Rephrasing
A synthetic rephrasing framework that enhances token utility without overfitting:
- Style-diverse prompting for linguistic variety while maintaining factual integrity
- Chunk-wise autoregressive generation to preserve global coherence in long documents
- Fidelity verification to ensure semantic consistency between original and rephrased content

Mathematics Data Enhancement
High-quality mathematical documents are rewritten into "learning-note" style, and materials from other languages are translated to English, significantly boosting mathematical reasoning capabilities.
Why This Matters
Kimi K2 represents more than incremental progress – it's a paradigm shift that:
Democratizes Advanced AI Capabilities
By achieving performance that rivals or exceeds leading proprietary models, Kimi K2 proves that cutting-edge AI capabilities need not be locked behind corporate walls.
Enables the "Verifier Economy"
The model's training approach suggests a future where AI systems consist of modular components: generators, simulators, and specialized verifiers, creating new opportunities for domain-specific AI products.
Validates System-Level Engineering
Kimi K2 demonstrates that breakthrough AI performance comes not just from scaling parameters, but from holistic innovation across optimizers, data pipelines, and alignment frameworks.
Accelerates Agentic Intelligence
With its focus on tool use and autonomous task execution, Kimi K2 pushes the field toward AI systems that can genuinely assist with complex, real-world problems.
Current Limitations and Future Directions
Kimi K2 acknowledges certain limitations while pointing toward future opportunities:
Current Constraints:
- Text-only modality (lacking vision capabilities)
- 128K context window (smaller than some competitors)
- Potential verbosity in complex reasoning tasks
- "Non-thinking" architecture (unlike deliberative reasoning models)
Future Opportunities:
- Multimodal capabilities development
- Extended context windows
- Enhanced reasoning frameworks
- Optimized long-context performance
Deployment and Accessibility
While Kimi K2's MoE architecture improves efficiency, deploying the full model still requires substantial hardware:
- Full precision: ~16 H200 GPUs
- Quantized versions: Multiple high-memory GPUs
- Inference services: Providers like OpenRouter and DeepInfra enable broader access
The open-source release ensures these advances benefit the entire AI community, with both base and instruction-tuned checkpoints available for research and commercial use.
Conclusion
Kimi K2 stands as a testament to the power of principled engineering and open research. By successfully combining token-efficient training, large-scale synthetic data generation, and innovative alignment techniques, Moonshot AI has created not just a powerful model, but a blueprint for the future of agentic intelligence.
The model's open-source release ensures that these advances benefit the entire AI community, accelerating progress toward AI systems that can truly understand, plan, and act in our complex world. As we move toward an era where AI agents become integral to how we work and solve problems, Kimi K2 provides both the technical foundation and the proof of concept for what's possible when ambition meets rigorous engineering.
The release of Kimi K2 marks a pivotal moment in AI development – one where the boundaries between research and practical application continue to blur, and where the democratization of advanced AI capabilities opens new possibilities for innovation across industries and applications.